Papers
equal contribution (*), corresponding authors (#)
2026
- Segmenting Human-LLM Co-authored Text via Change Point DetectionMengchu Li*, Jin Zhu*, Jinglai Li, and Chengchun ShiStatistics and Trustworthy AI for Cross (X)-Domain Acceleration, 2026
The rise of large language models (LLMs) has created an urgent need to distinguish between human-written and LLM-generated text to ensure authenticity and societal trust. Existing detectors typically provide a binary classification for an entire passage; however, this is insufficient for human–LLM co-authored text, where the objective is to localize specific segments authored by humans or LLMs. To bridge this gap, we propose algorithms to segment text into human- and LLM-authored pieces. Our key observation is that such a segmentation task is conceptually similar to classical change point detection in time-series analysis. Leveraging this analogy, we adapt change point detection to LLM-generated text detection, develop a weighted algorithm and a generalized algorithm to accommodate heterogeneous detection score variability, and establish the minimax optimality of our procedure. Empirically, we demonstrate the strong performance of our approach against a wide range of existing baselines.
- Learning Perturbations to Extrapolate Your LLMStatistics and Trustworthy AI for Cross (X)-Domain Acceleration, 2026
Recent advancements in large language models demonstrate that injecting perturbations can substantially enhance extrapolation performance. However, current approaches often rely on discrete perturbations with fixed designs, which limits their flexibility. In this work, we propose a framework where token prefixes are perturbed by a learnable transformation of a continuous latent vector within an embedding space. To overcome the challenge of an intractable marginal likelihood, we derive unbiased estimating equations for model parameters and optimize them via stochastic gradient descent. We establish the statistical properties of the resulting estimator in over-parameterized regimes. Empirical evaluations on both synthetic and real-world datasets demonstrate that our proposal yields significant gains in out-of-domain settings over a range of state-of-the-art baseline methods.
- READER: Reasoning-Enhanced AI-Generated Text DetectionarXiv preprint arXiv:2605.25281, 2026
Recent advances in large language models (LLMs) have made it increasingly difficult to distinguish human-written text from AI-generated content. Many existing detectors train supervised neural classifiers that achieve strong in-distribution performance but are often opaque and can degrade substantially under distribution shift. We present READER, a reasoning-enhanced AI text detector that outputs both a human/AI label and a structured rationale describing the evidence for its decision. A key component of our approach is READ, a curated supervision set of rationales and verdicts. We fine-tune an LLM on READ to build READER, which reasons before detecting at inference time. Despite having only 1.5B parameters, READER consistently outperforms existing detectors as well as prompted, high-capacity LLM baselines (GPT-5.2, Gemini-3-Pro, and DeepSeek-V3.2), which are 100 to 1000 times larger in scale.
- Perturbation is All You Need for Extrapolating Language ModelsZetai Cen*, Jin Zhu*, Xinwei Shen, and Chengchun ShiarXiv preprint arXiv:2605.04344, 2026
We introduce a simple yet powerful framework for training large language models. In contrast to the standard autoregressive next-token prediction based on an exact prefix, we propose a perturbation-based procedure that first transforms the prefix into a semantic neighbor and then conditions on this perturbed variant for next-token prediction. This yields a hierarchical model with a pre-post-additive noise structure. Within this framework, we develop a rigorous theory of extrapolability, namely, the capacity of a model class to make reliable predictions for token sequences that lie outside the empirical support of the training corpus. We evaluate the finite-sample performance of the proposed procedure using both synthetic and real-world language data. Results show that the proposed method consistently improves out-of-support prediction while maintaining competitive in-support performance, demonstrating that perturbation offers a practical route to language modeling.
- Sequential Knockoffs for Variable Selection in Reinforcement LearningJournal of the American Statistical Association, 2026
In real-world applications of reinforcement learning, it is often challenging to obtain a state representation that is parsimonious and satisfies the Markov property without prior knowledge. Consequently, it is common practice to construct a state larger than necessary, e.g., by concatenating measurements over contiguous time points. However, needlessly increasing the dimension of the state may slow learning and obfuscate the learned policy. We introduce the notion of a minimal sufficient state in a Markov decision process (MDP) as the subvector of the original state under which the process remains an MDP and shares the same reward function as the original process. We propose a novel sequential knockoffs (SEEK) algorithm that estimates the minimal sufficient state in a system with high-dimensional complex nonlinear dynamics. In large samples, the proposed method achieves selection consistency. As the method is agnostic to the reinforcement learning algorithm being applied, it benefits downstream tasks such as policy learning. Empirical experiments verify theoretical results and show that the proposed approach outperforms several competing methods regarding variable selection accuracy and the suboptimality gap of the learned policy. A Python implementation of SEEK is provided at https://github.com/Mamba413/seek.
- Kernelized Advantage Estimation: From Nonparametric Statistics to LLM ReasoningarXiv preprint arXiv:2604.28005v1, 2026
Recent advances in large language models (LLMs) have increasingly relied on reinforcement learning (RL) to improve their reasoning capabilities. Three approaches have been widely adopted: (i) Proximal policy optimization and advantage actor-critic rely on a deep neural network to estimate the value function of the learning policy in order to reduce the variance of the policy gradient. However, estimating and maintaining such a value network incurs substantial computational and memory overhead. (ii) Group relative policy optimization (GRPO) avoids training a value network by approximating the value function using sample averages. However, GRPO samples a large number of reasoning traces per prompt to achieve accurate value function approximation, making it computationally expensive. (iii) REINFORCE-type algorithms sample only a single reasoning trajectory per prompt, which reduces computational cost but suffers from poor sample efficiency. In this work, we focus on a practical, resource-constrained setting in which only a small number of reasoning traces can be sampled per prompt, while low-variance gradient estimation remains essential for high-quality policy learning. To address this challenge, we bring classical nonparametric statistical methods, which are both computationally and statistically efficient, to LLM reasoning. We employ kernel smoothing as a concrete example for value function estimation and the subsequent policy optimization. Numerical and theoretical results demonstrate that our proposal achieves accurate value and gradient estimation, leading to improved policy optimization.
- Demystifying Group Relative Policy Optimization: Its Policy Gradient is a U-StatisticarXiv preprint arXiv:2603.01162, 2026
Group relative policy optimization (GRPO), a core methodological component of DeepSeekMath and DeepSeek-R1, has emerged as a cornerstone for scaling reasoning capabilities of large language models. Despite its widespread adoption and the proliferation of follow-up works, the theoretical properties of GRPO remain less studied. This paper provides a unified framework to understand GRPO through the lens of classical U-statistics. We demonstrate that the GRPO policy gradient is inherently a U-statistic, allowing us to characterize its mean squared error (MSE), derive the finite-sample error bound and asymptotic distribution of the suboptimality gap for its learned policy. Our findings reveal that GRPO is asymptotically equivalent to an oracle policy gradient algorithm – one with access to a value function that quantifies the goodness of its learning policy at each training iteration – and achieves asymptotically optimal performance within a broad class of policy gradient algorithms. Furthermore, we establish a universal scaling law that offers principled guidance for selecting the optimal group size. Empirical experiments further validate our theoretical findings, demonstrating that the optimal group size is universal, and verify the oracle property of GRPO.
- A Difference-in-Difference Approach to Detecting AI-Generated ImagesXinyi Qi*, Kai Ye*, Chengchun Shi, Ying Yang, Hongyi Zhou#, and Jin Zhu#In Computer Vision and Pattern Recognition, 2026
Diffusion models are able to produce AI-generated images that are almost indistinguishable from real ones. This raises concerns about their potential misuse and poses substantial challenges for detecting them. Many existing detectors rely on reconstruction error — the difference between the input image and its reconstructed version — as the basis for distinguishing real from fake images. However, these detectors become less effective as modern AI-generated images become increasingly similar to real ones. To address this challenge, we propose a novel difference-in-difference method. Instead of directly using the reconstruction error (a first-order difference), we compute the difference in reconstruction error – a second-order difference – for variance reduction and improving detection accuracy. Extensive experiments demonstrate that our method achieves strong generalization performance, enabling reliable detection of AI-generated images in the era of generative AI.
- Learn-to-Distance: Distance Learning for Detecting LLM-Generated TextIn The Fourteenth International Conference on Learning Representations, 2026
Modern large language models (LLMs) such as GPT, Claude, and Gemini have transformed the way we learn, work, and communicate. Yet, their ability to produce highly human-like text raises serious concerns about misinformation and academic integrity, making it an urgent need for reliable algorithms to detect LLM-generated content. In this paper, we start by presenting a geometric approach to demystify rewrite-based detection algorithms, revealing their underlying rationale and demonstrating their generalization ability. Building on this insight, we introduce a novel rewrite-based detection algorithm that adaptively learns the distance between the original and rewritten text. Theoretically, we demonstrate that employing an adaptively learned distance function is more effective for detection than using a fixed distance. Empirically, we conduct extensive experiments with over 100 settings, and find that our approach demonstrates superior performance over baseline algorithms in the majority of scenarios. In particular, it achieves relative improvements from 57.8% to 80.6% over the strongest baseline across different target LLMs (e.g., GPT, Claude, and Gemini).
- Detecting LLM-Generated Text with Performance GuaranteesarXiv preprint arXiv:2601.06586, 2026
Large language models (LLMs) such as GPT, Claude, Gemini, and Grok have been deeply integrated into our daily life. They now support a wide range of tasks – from dialogue and email drafting to assisting with teaching and coding, serving as search engines, and much more. However, their ability to produce highly human-like text raises serious concerns, including the spread of fake news, the generation of misleading governmental reports, and academic misconduct. To address this practical problem, we train a classifier to determine whether a piece of text is authored by an LLM or a human. Our detector is deployed on an online CPU-based platform https://huggingface.co/spaces/stats-powered-ai/StatDetectLLM, and contains three novelties over existing detectors: (i) it does not rely on auxiliary information, such as watermarks or knowledge of the specific LLM used to generate the text; (ii) it more effectively distinguishes between human- and LLM-authored text; and (iii) it enables statistical inference, which is largely absent in the current literature. Empirically, our classifier achieves higher classification accuracy compared to existing detectors, while maintaining type-I error control, high statistical power, and computational efficiency.
- AoASIdentification of Genetic Factors Associated with Corpus Callosum Morphology: Conditional Strong Independence Screening for Non-Euclidean ResponsesZhe Gao*, Jin Zhu*, Yue Hu, Wenliang Pan, and Xueqin WangAnnals of Applied Statistics, 2026
The corpus callosum, the largest white matter structure in the brain, plays a critical role in interhemispheric communication. Variations in its morphology are associated with various neurological and psychological conditions, making it a key focus in neurogenetics. Age is known to influence the structure and morphology of the corpus callosum significantly, complicating the identification of specific genetic factors that contribute to its shape and size. We propose a conditional strong independence screening method to address these challenges for ultrahigh-dimensional predictors and non-Euclidean responses, incorporating prior knowledge such as age through a novel concept of conditional metric dependence, which quantifies nonlinear conditional dependencies among random objects in metric spaces without relying on predefined models. We apply this framework to identify genetic factors associated with the morphology of the corpus callosum. Simulation results demonstrate the efficacy of this method across various non-Euclidean data types, highlighting its potential to drive genetic discovery in neuroscience.
- Reconstruct Ising Model with Global Optimality via SLIDEXuanyu Chen*, Jin Zhu*, Junxian Zhu*, Xueqin Wang, and Heping ZhangJournal of the American Statistical Association, 2026
The reconstruction of interaction networks between random events is a critical problem arising from statistical physics and politics, sociology, biology, psychology, and beyond. The Ising model lays the foundation for this reconstruction process, but finding the underlying Ising model from the least amount of observed samples in a computationally efficient manner has been historically challenging for half a century. Using sparsity learning, we present an approach named SLIDE whose sample complexity is globally optimal. Furthermore, a tuning-free algorithm is developed to give a statistically consistent solution of SLIDE in polynomial time with high probability. On extensive benchmarked cases, the SLIDE approach demonstrates dominant performance in reconstructing underlying Ising models, confirming its superior statistical properties. The application on the U.S. senators voting in the last six congresses reveals that both the Republicans and Democrats noticeably assemble in each congress; interestingly, the assembling of Democrats is particularly pronounced in the latest congress.
2025
- AdaDetectGPT: Adaptive Detection of LLM-Generated Text with Statistical GuaranteesHongyi Zhou*, Jin Zhu*, Pingfan Su, Kai Ye, Ying Yang, Shakeel A O B Gavioli-Akilagun, and Chengchun Shi2025
We study the problem of determining whether a piece of text has been authored by a human or by a large language model (LLM). Existing state of the art logits-based detectors make use of statistics derived from the log-probability of the observed text evaluated using the distribution function of a given source LLM. However, relying solely on log probabilities can be sub-optimal. In response, we introduce AdaDetectGPT – a novel classifier that adaptively learns a witness function from training data to enhance the performance of logits-based detectors. We provide statistical guarantees on its true positive rate, false positive rate, true negative rate and false negative rate. Extensive numerical studies show AdaDetectGPT nearly uniformly improves the state-of-the-art method in various combination of datasets and LLMs, and the improvement can reach up to 58%.
- Simplex Constrained Sparse Optimization via Tail ScreeningPeng Chen*, Jin Zhu*, Junxian Zhu*, and Xueqin WangJournal of Machine Learning Research, 2025
We consider the probabilistic simplex-constrained sparse recovery problem. The commonly used Lasso-type penalty for promoting sparsity is ineffective in this context since it is a constant within the simplex. Despite this challenge, fortunately, simplex constraint itself brings a self-regularization property, i.e., the empirical risk minimizer without any sparsity-promoting procedure obtains the usual Lasso-type estimation error. Moreover, we analyze the iterates of a projected gradient descent method and show its convergence to the ground truth sparse solution in the geometric rate until a satisfied statistical precision is attained. Although the estimation error is statistically optimal, the resulting solution is usually more dense than the sparse ground truth. To further sparsify the iterates, we propose a method called PERMITS via embedding a tail screening procedure, i.e., identifying negligible components and discarding them during iterations, into the projected gradient descent method. Furthermore, we combine tail screening and the special information criterion to balance the trade-off between fitness and complexity. Theoretically, the proposed PERMITS method can exactly recover the ground truth support set under mild conditions and thus obtain the oracle property. We demonstrate the statistical and computational efficiency of PERMITS with both synthetic and real data. The implementation of the proposed method can be found in https://github.com/abess-team/PERMITS.
- Balancing Interference and Correlation in Spatial Experimental Designs: A Causal Graph Cut ApproachIn Proceedings of the 42nd International Conference on Machine Learning, 13–19 jul 2025
This paper focuses on the design of spatial experiments to optimize the amount of information derived from the experimental data and enhance the accuracy of the resulting causal effect estimator. We propose a surrogate function for the mean squared error (MSE) of the estimator, which facilitates the use of classical graph cut algorithms to learn the optimal design. Our proposal offers three key advances: (1) it accommodates moderate to large spatial interference effects; (2) it adapts to different spatial covariance functions; (3) it is computationally efficient. Theoretical results and numerical experiments based on synthetic environments and a dispatch simulator that models a city-scale ridesharing market, further validate the effectiveness of our design. A python implementation of our method is available at https://github.com/Mamba413/CausalGraphCut.
- Demystifying the Paradox of Importance Sampling with an Estimated History-Dependent Behavior Policy in Off-Policy EvaluationIn Proceedings of the 42nd International Conference on Machine Learning, 13–19 jul 2025
This paper studies off-policy evaluation (OPE) in reinforcement learning with a focus on behavior policy estimation for importance sampling. Prior work has shown empirically that estimating a history-dependent behavior policy can lead to lower mean squared error (MSE) even when the true behavior policy is Markovian. However, the question of why the use of history should lower MSE remains open. In this paper, we theoretically demystify this paradox by deriving a bias-variance decomposition of the MSE of ordinary importance sampling (IS) estimators, demonstrating that history-dependent behavior policy estimation decreases their asymptotic variances while increasing their finite-sample biases. Additionally, as the estimated behavior policy conditions on a longer history, we show a consistent decrease in variance. We extend these findings to a range of other OPE estimators, including the sequential IS estimator, the doubly robust estimator and the marginalized IS estimator, with the behavior policy estimated either parametrically or non-parametrically.
- Semi-pessimistic Reinforcement LearningJin Zhu, Xin Zhou, Jiaang Yao, Gholamali Aminian, Omar Rivasplata, Simon Little, Lexin Li, and Chengchun ShiarXiv preprint arXiv:2505.19002, 13–19 jul 2025
Offline reinforcement learning (RL) aims to learn an optimal policy from pre-collected data. However, it faces challenges of distributional shift, where the learned policy may encounter unseen scenarios not covered in the offline data. Additionally, numerous applications suffer from a scarcity of labeled reward data. Relying on labeled data alone often leads to a narrow state-action distribution, further amplifying the distributional shift, and resulting in suboptimal policy learning. To address these issues, we first recognize that the volume of unlabeled data is typically substantially larger than that of labeled data. We then propose a semi-pessimistic RL method to effectively leverage abundant unlabeled data. Our approach offers several advantages. It considerably simplifies the learning process, as it seeks a lower bound of the reward function, rather than that of the Q-function or state transition function. It is highly flexible, and can be integrated with a range of model-free and model-based RL algorithms. It enjoys the guaranteed improvement when utilizing vast unlabeled data, but requires much less restrictive conditions. We compare our method with a number of alternative solutions, both analytically and numerically, and demonstrate its clear competitiveness. We further illustrate with an application to adaptive deep brain stimulation for Parkinson’s disease.
- ICML WorkshopRobust Reinforcement Learning from Human Feedback for Large Language Models Fine-TuningKai Ye*, Hongyi Zhou*, Jin Zhu*, Francesco Quinzan, and Chengchung ShiarXiv preprint arXiv:2504.03784, 13–19 jul 2025
Reinforcement learning from human feedback (RLHF) has emerged as a key technique for aligning the output of large language models (LLMs) with human preferences. To learn the reward function, most existing RLHF algorithms use the Bradley-Terry model, which relies on assumptions about human preferences that may not reflect the complexity and variability of real-world judgments. In this paper, we propose a robust algorithm to enhance the performance of existing approaches under such reward model misspecifications. Theoretically, our algorithm reduces the variance of reward and policy estimators, leading to improved regret bounds. Empirical evaluations on LLM benchmark datasets demonstrate that the proposed algorithm consistently outperforms existing methods, with 77-81% of responses being favored over baselines on the Anthropic Helpful and Harmless dataset.
2024
- skscope: Fast Sparsity-Constrained Optimization in PythonZezhi Wang, Junxian Zhu, Xueqin Wang, Jin Zhu, Peng Chen, Huiyang Peng, Anran Wang, and Xiaoke ZhangJournal of Machine Learning Research, 13–19 jul 2024
Applying iterative solvers on sparsity-constrained optimization (SCO) requires tedious mathematical deduction and careful programming/debugging that hinders these solvers’ broad impact. In the paper, the library skscope is introduced to overcome such an obstacle. With skscope, users can solve the SCO by just programming the objective function. The convenience of skscope is demonstrated through two examples in the paper, where sparse linear regression and trend filtering are addressed with just four lines of code. More importantly, skscope’s efficient implementation allows state-of-the-art solvers to quickly attain the sparse solution regardless of the high dimensionality of parameter space. Numerical experiments reveal the available solvers in skscope can achieve up to 80x speedup on the competing relaxation solutions obtained via the benchmarked convex solver. skscope is published on the Python Package Index (PyPI) and Conda, and its source code is available at: https://github.com/abess-team/skscope.
- Robust Offline Reinforcement Learning with Heavy-Tailed RewardsIn The 27th International Conference on Artificial Intelligence and Statistics, 13–19 jul 2024
This paper endeavors to augment the robustness of offline reinforcement learning (RL) in scenarios laden with heavy-tailed rewards, a prevalent circumstance in real-world applications. We propose two algorithmic frameworks, ROAM and ROOM, for robust off-policy evaluation (OPE) and offline policy optimization (OPO), respectively. Central to our frameworks is the strategic incorporation of the median-of-means method with offline RL, enabling straightforward uncertainty estimation for the value function estimator. This not only adheres to the principle of pessimism in OPO but also adeptly manages heavy-tailed rewards. Theoretical results and extensive experiments demonstrate that our two frameworks outperform existing methods on the logged dataset exhibits heavy-tailed reward distributions.
2023
- Nonparametric Statistical Inference via Metric Distribution Function in Metric SpacesXueqin Wang*, Jin Zhu*, Wenliang Pan*, Junhao Zhu*, and Heping Zhang*Journal of the American Statistical Association, 13–19 jul 2023
Distribution function is essential in statistical inference, and connected with samples to form a directed closed loop by the correspondence theorem in measure theory and the Glivenko-Cantelli and Donsker properties. This connection creates a paradigm for statistical inference. However, existing distribution functions are defined in Euclidean spaces and no longer convenient to use in rapidly evolving data objects of complex nature. It is imperative to develop the concept of distribution function in a more general space to meet emerging needs. Note that the linearity allows us to use hypercubes to define the distribution function in a Euclidean space, but without the linearity in a metric space, we must work with the metric to investigate the probability measure. We introduce a class of metric distribution functions through the metric between random objects and a fixed location in metric spaces. We overcome this challenging step by proving the correspondence theorem and the Glivenko-Cantelli theorem for metric distribution functions in metric spaces that lie the foundation for conducting rational statistical inference for metric space-valued data. Then, we develop homogeneity test and mutual independence test for non-Euclidean random objects, and present comprehensive empirical evidence to support the performance of our proposed methods.
- A Consistent and Scalable Algorithm for Best Subset Selection in Single Index ModelsBorui Tang*, Jin Zhu*, Junxian Zhu*, Xueqin Wang, and Heping ZhangarXiv, 13–19 jul 2023
Analysis of high-dimensional data has led to increased interest in both single index models (SIMs) and best subset selection. SIMs provide an interpretable and flexible modeling framework for high-dimensional data, while best subset selection aims to find a sparse model from a large set of predictors. However, best subset selection in high-dimensional models is known to be computationally intractable. Existing methods tend to relax the selection, but do not yield the best subset solution. In this paper, we directly tackle the intractability by proposing the first provably scalable algorithm for best subset selection in high-dimensional SIMs. Our algorithmic solution enjoys the subset selection consistency and has the oracle property with a high probability. The algorithm comprises a generalized information criterion to determine the support size of the regression coefficients, eliminating the model selection tuning. Moreover, our method does not assume an error distribution or a specific link function and hence is flexible to apply. Extensive simulation results demonstrate that our method is not only computationally efficient but also able to exactly recover the best subset in various settings (e.g., linear regression, Poisson regression, heteroscedastic models).
- Best-subset selection in generalized linear models: A fast and consistent algorithm via splicing techniqueJunxian Zhu, Jin Zhu, Borui Tang, Xuanyu Chen, Hongmei Lin, and Xueqin WangarXiv, 13–19 jul 2023
In high-dimensional generalized linear models, it is crucial to identify a sparse model that adequately accounts for response variation. Although the best subset section has been widely regarded as the Holy Grail of problems of this type, achieving either computational efficiency or statistical guarantees is challenging. In this article, we intend to surmount this obstacle by utilizing a fast algorithm to select the best subset with high certainty. We proposed and illustrated an algorithm for best subset recovery in regularity conditions. Under mild conditions, the computational complexity of our algorithm scales polynomially with sample size and dimension. In addition to demonstrating the statistical properties of our method, extensive numerical experiments reveal that it outperforms existing methods for variable selection and coefficient estimation. The runtime analysis shows that our implementation achieves approximately a fourfold speedup compared to popular variable selection toolkits like glmnet and ncvreg.
- An Instrumental Variable Approach to Confounded Off-Policy EvaluationYang Xu, Jin Zhu, Chengchun Shi, Shikai Luo, and Rui SongIn Proceedings of the 40th International Conference on Machine Learning, 13–19 jul 2023
Off-policy evaluation (OPE) aims to estimate the return of a target policy using some pre-collected observational data generated by a potentially different behavior policy. In many cases, there exist unmeasured variables that confound the action-reward or action-next-state relationships, rendering many existing OPE approaches ineffective. This paper develops an instrumental variable (IV)-based method for consistent OPE in confounded sequential decision making. Similar to single-stage decision making, we show that IV enables us to correctly identify the target policy’s value in infinite horizon settings as well. Furthermore, we propose a number of policy value estimators and illustrate their effectiveness through extensive simulations and real data analysis from a world-leading short-video platform.
- A Splicing Approach to Best Subset of Groups SelectionYanhang Zhang*, Junxian Zhu*, Jin Zhu*, and Xueqin WangINFORMS Journal on Computing, 13–19 jul 2023
Best subset of groups selection (BSGS) is the process of selecting a small part of nonoverlapping groups to achieve the best interpretability on the response variable. It has attracted increasing attention and has far-reaching applications in practice. However, due to the computational intractability of BSGS in high-dimensional settings, developing efficient algorithms for solving BSGS remains a research hotspot. In this paper, we propose a group-splicing algorithm that iteratively detects the relevant groups and excludes the irrelevant ones. Moreover, coupled with a novel group information criterion, we develop an adaptive algorithm to determine the optimal model size. Under certain conditions, it is certifiable that our algorithm can identify the optimal subset of groups in polynomial time with high probability. Finally, we demonstrate the efficiency and accuracy of our methods by comparing them with several state-of-the-art algorithms on both synthetic and real-world data sets.
2022
- Quantiles, Ranks and Signs in Metric SpacesHang Liu, Xueqin Wang, and Jin ZhuarXiv, 13–19 jul 2022
Non-Euclidean data is currently prevalent in many fields, necessitating the development of novel concepts such as distribution functions, quantiles, rankings, and signs for these data in order to conduct nonparametric statistical inference. This study provides new thoughts on quantiles, both locally and globally, in metric spaces. This is realized by expanding upon metric distribution function proposed by Wang et al. (2021). Rank and sign are defined at both the local and global levels as a natural consequence of the center-outward ordering of metric spaces brought about by the local and global quantiles. The theoretical properties are established, such as the root-n consistency and uniform consistency of the local and global empirical quantiles and the distribution-freeness of ranks and signs. The empirical metric median, which is defined here as the 0th empirical global metric quantile, is proven to be resistant to contaminations by means of both theoretical and numerical approaches. Quantiles have been shown valuable through extensive simulations in a number of metric spaces. Moreover, we introduce a family of fast rank-based independence tests for a generic metric space. Monte Carlo experiments show good finite-sample performance of the test. Quantiles are demonstrated in a real-world setting by analysing hippocampal data.
- abess: A Fast Best-Subset Selection Library in Python and RJin Zhu, Xueqin Wang, Liyuan Hu, Junhao Huang, Kangkang Jiang, Yanhang Zhang, Shiyun Lin, and Junxian ZhuJournal of Machine Learning Research, 13–19 jul 2022
We introduce a new library named abess that implements a unified framework of best-subset selection for solving diverse machine learning problems, e.g., linear regression, classification, and principal component analysis. Particularly, abess certifiably gets the optimal solution within polynomial time with high probability under the linear model. Our efficient implementation allows abess to attain the solution of best-subset selection problems as fast as or even 20x faster than existing competing variable (model) selection toolboxes. Furthermore, it supports common variants like best subset of groups selection and l2 regularized best-subset selection. The core of the library is programmed in C++. For ease of use, a Python library is designed for convenient integration with scikit-learn, and it can be installed from the Python Package Index (PyPI). In addition, a user-friendly R library is available at the Comprehensive R Archive Network (CRAN). The source code is available at: https://github.com/abess-team/abess.
- Off-Policy Confidence Interval Estimation with Confounded Markov Decision ProcessJournal of the American Statistical Association, 13–19 jul 2022
This paper is concerned with constructing a confidence interval for a target policy’s value offline based on a pre-collected observational data in infinite horizon settings. Most of the existing works assume no unmeasured variables exist that confound the observed actions. This assumption, however, is likely to be violated in real applications such as healthcare and technological industries. In this paper, we show that with some auxiliary variables that mediate the effect of actions on the system dynamics, the target policy’s value is identifiable in a confounded Markov decision process. Based on this result, we develop an efficient off-policy value estimator that is robust to potential model misspecification and provide rigorous uncertainty quantification. Our method is justified by theoretical results, simulated and real datasets obtained from ridesharing companies. A Python implementation of the proposed procedure is available at https://github.com/Mamba413/cope.
- Paired-sample tests for homogeneity with/without confounding variablesMinqiong Chen, Ting Tian, Jin Zhu, Wenliang Pan, and Xueqin WangStatistics and Its Interface, 13–19 jul 2022
In this article, we are concerned about testing the homogeneity on paired samples with or without confounding variables. These problems usually arise in clinical trials, psychological or sociological studies. We introduce new nonparametric tests for equality of two distributions or two conditional distributions of random vectors on paired samples. We show that their test statistics are consistent but have different asymptotic distributions under the null hypothesis, depending on whether confounding variables exist. The limit distribution of the test statistic is a mixed χ^2 distribution when testing the equality of two paired distributions, while it is a normal distribution when testing the equality of two conditional distributions of paired samples. We conduct several simulation studies to evaluate the finite-sample performance of our tests. Finally, we apply our tests on real data to illustrate their usefulness in the applications.
-
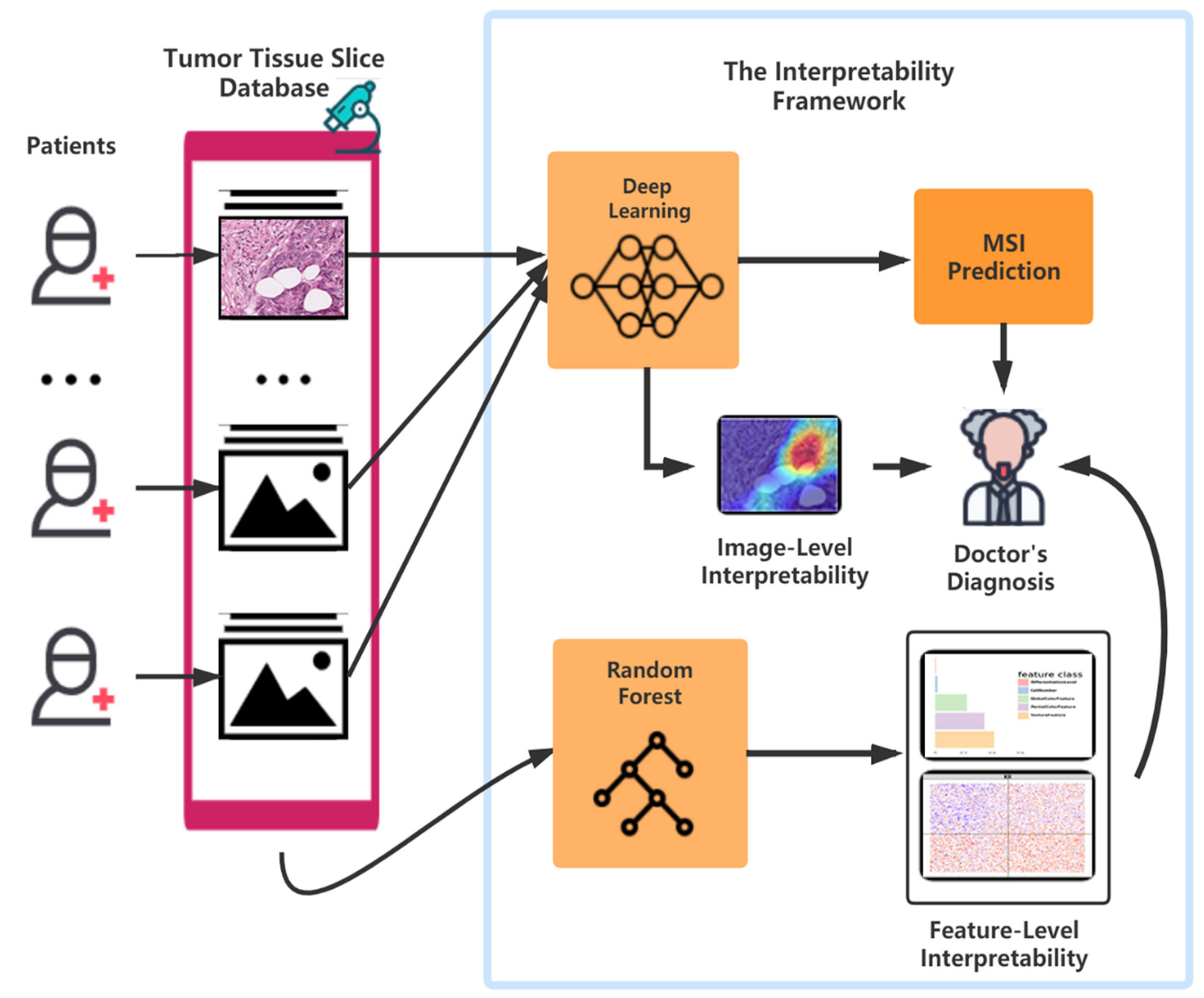 Computational Analysis of Pathological Image Enables Interpretable Prediction for Microsatellite InstabilityJin Zhu, Wangwei Wu, Yuting Zhang, Shiyun Lin, Yukang Jiang, Ruixian Liu, Heping Zhang, and Xueqin WangFrontiers in Oncology, 13–19 jul 2022
Computational Analysis of Pathological Image Enables Interpretable Prediction for Microsatellite InstabilityJin Zhu, Wangwei Wu, Yuting Zhang, Shiyun Lin, Yukang Jiang, Ruixian Liu, Heping Zhang, and Xueqin WangFrontiers in Oncology, 13–19 jul 2022

2021
- Ball: An R package for detecting distribution difference and association in metric spacesJin Zhu, Wenliang Pan, Wei Zheng, and Xueqin WangJournal of Statistical Software, 13–19 jul 2021
The rapid development of modern technology has created many complex datasets in non-linear spaces, while most of the statistical hypothesis tests are only available in Euclidean or Hilbert spaces. To properly analyze the data with more complicated structures, efforts have been made to solve the fundamental test problems in more general spaces (Lyons 2013; Pan, Tian, Wang, and Zhang 2018; Pan, Wang, Zhang, Zhu, and Zhu 2020). In this paper, we introduce a publicly available R package Ball for the comparison of multiple distributions and the test of mutual independence in metric spaces, which extends the test procedures for the equality of two distributions (Pan et al. 2018) and the independence of two random objects (Pan et al. 2020). The Ball package is computationally efficient since several novel algorithms as well as engineering techniques are employed in speeding up the ball test procedures. Two real data analyses and diverse numerical studies have been performed, and the results certify that the Ball package can detect various distribution differences and complicated dependencies in complex datasets, e.g., directional data and symmetric positive definite matrix data.
-
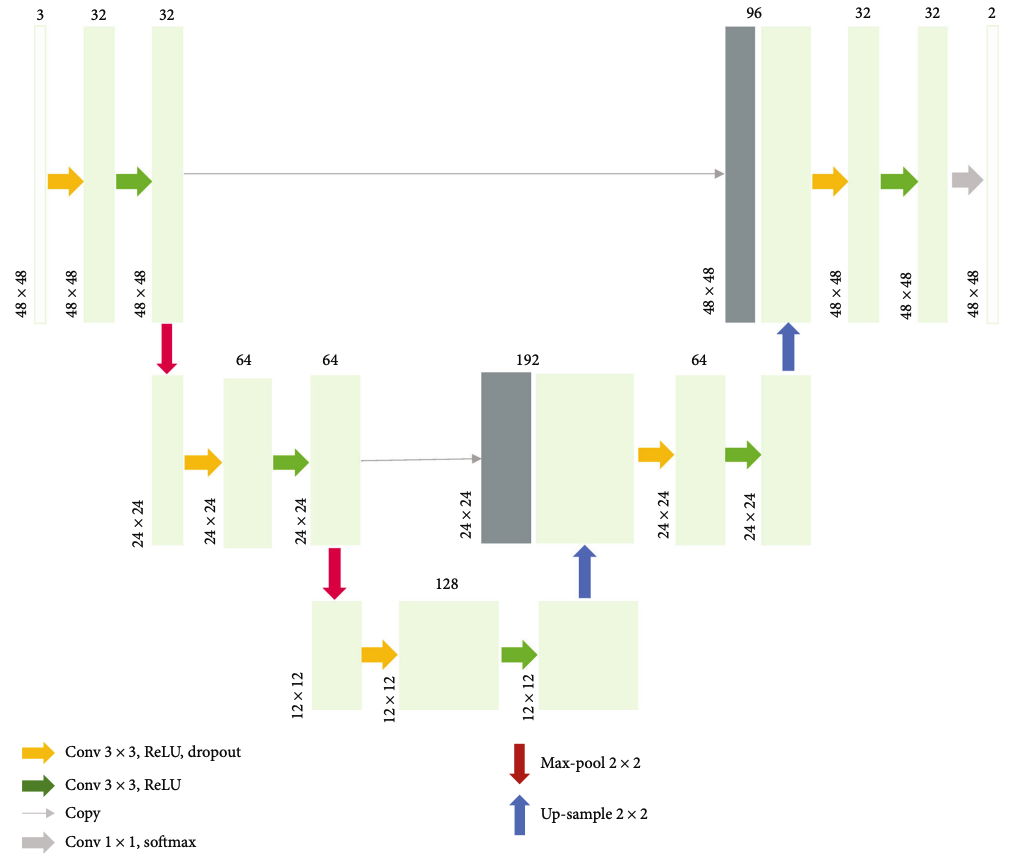 Segmentation of Laser Marks of Diabetic Retinopathy in the Fundus Photographs Using Lightweight U-NetYukang Jiang, Jianying Pan, Ming Yuan, Yanhe Shen, Jin Zhu, Yishen Wang, Yewei Li, Ke Zhang, Qingyun Yu, Huirui Xie, Huiting Li, Xueqin Wang, and Yan LuoJournal of Diabetes Research, Oct 2021
Segmentation of Laser Marks of Diabetic Retinopathy in the Fundus Photographs Using Lightweight U-NetYukang Jiang, Jianying Pan, Ming Yuan, Yanhe Shen, Jin Zhu, Yishen Wang, Yewei Li, Ke Zhang, Qingyun Yu, Huirui Xie, Huiting Li, Xueqin Wang, and Yan LuoJournal of Diabetes Research, Oct 2021Diabetic retinopathy (DR) is a prevalent vision-threatening disease worldwide. Laser marks are the scars left after panretinal photocoagulation, a treatment to prevent patients with severe DR from losing vision. In this study, we develop a deep learning algorithm based on the lightweight U-Net to segment laser marks from the color fundus photos, which could help indicate a stage or providing valuable auxiliary information for the care of DR patients. We prepared our training and testing data, manually annotated by trained and experienced graders from Image Reading Center, Zhongshan Ophthalmic Center, publicly available to fill the vacancy of public image datasets dedicated to the segmentation of laser marks. The lightweight U-Net, along with two postprocessing procedures, achieved an AUC of 0.9824, an optimal sensitivity of 94.16%, and an optimal specificity of 92.82% on the segmentation of laser marks in fundus photographs. With accurate segmentation and high numeric metrics, the lightweight U-Net method showed its reliable performance in automatically segmenting laser marks in fundus photographs, which could help the AI assist the diagnosis of DR in the severe stage.

2020
- A polynomial algorithm for best subset selection problemJunXian Zhu, CanHong Wen, Jin Zhu, XueQin Wang, and HePing ZhangProceedings of the National Academy of Sciences, Oct 2020
Best-subset selection aims to find a small subset of predictors, so that the resulting linear model is expected to have the most desirable prediction accuracy. It is not only important and imperative in regression analysis but also has far-reaching applications in every facet of research, including computer science and medicine. We introduce a polynomial algorithm, which, under mild conditions, solves the problem. This algorithm exploits the idea of sequencing and splicing to reach a stable solution in finite steps when the sparsity level of the model is fixed but unknown. We define an information criterion that helps the algorithm select the true sparsity level with a high probability. We show that when the algorithm produces a stable optimal solution, that solution is the oracle estimator of the true parameters with probability one. We also demonstrate the power of the algorithm in several numerical studies.
- Ball covariance: A generic measure of dependence in banach spaceWenliang Pan*, Xueqin Wang*, Heping Zhang*, Hongtu Zhu*, and Jin Zhu*Journal of the American Statistical Association, Oct 2020
Technological advances in science and engineering have led to the routine collection of large and complex data objects, where the dependence structure among those objects is often of great interest. Those complex objects (e.g., different brain subcortical structures) often reside in some Banach spaces, and hence their relationship cannot be well characterized by most of the existing measures of dependence such as correlation coefficients developed in Hilbert spaces. To overcome the limitations of the existing measures, we propose Ball Covariance as a generic measure of dependence between two random objects in two possibly different Banach spaces. Our Ball Covariance possesses the following attractive properties: (i) It is nonparametric and model-free, which make the proposed measure robust to model mis-specification; (ii) It is nonnegative and equal to zero if and only if two random objects in two separable Banach spaces are independent; (iii) Empirical Ball Covariance is easy to compute and can be used as a test statistic of independence. We present both theoretical and numerical results to reveal the potential power of the Ball Covariance in detecting dependence. Also importantly, we analyze two real datasets to demonstrate the usefulness of Ball Covariance in the complex dependence detection.
2019
-
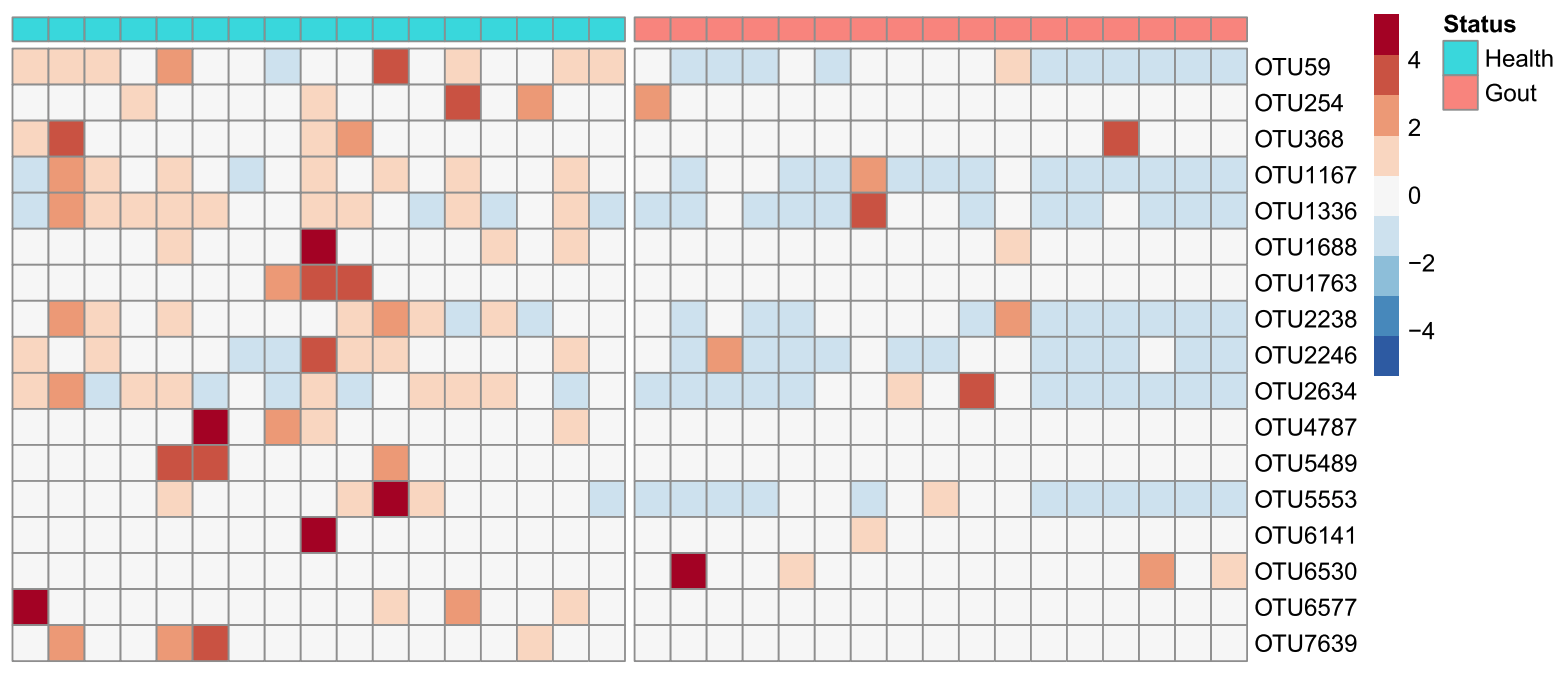 Two-sample test for compositional data with ball divergenceJin Zhu, Kunsheng Lv, Aijun Zhang, Wenliang Pan, and Xueqin WangStatistics and Its Interface, Oct 2019
Two-sample test for compositional data with ball divergenceJin Zhu, Kunsheng Lv, Aijun Zhang, Wenliang Pan, and Xueqin WangStatistics and Its Interface, Oct 2019In this paper, we try to analyze whether the intestinal microbiota structures between gout patients and healthy individuals are different. The intestinal microbiota structures are usually measured by so-called compositional data, composed of multiple components whose value are typically non-negative and sum up to a constant. They are frequently collected and studied in many areas such as petrology, biology, and medicine nowadays. The difficulties to do statistical inference with compositional data arise from not only the constant restriction on the component sum, but also high dimensionality of the components with possible many zero measurements, which are frequently appeared in the 16S rRNA gene sequences. To overcome these difficulties, we first define the Bhattacharyya distance between two compositions such that the set of compositions is isometrically embedded in some spherical surfaces. And then we propose a two-sample test statistic for compositional data by Ball Divergence, a novel but powerful measure for the discrepancy between two probability measures in separable Banach spaces. Our test procedure demonstrates its excellent performance in Monte Carlo simulation studies even when the simulated data consist of thousand components with a high proportion of zero measurements. We also find that our method can distinguish two intestinal microbiota structures between gout patients and healthy individuals while the existing method does not.
